How we 80/20'ed the data warehouse
Jun 20, 2024






If David Attenborough made documentaries about tech products, he would definitely do one about the mythical data warehouse. Because he doesn't, I'll take you on that adventure myself.
We recently released the open beta of own data warehouse, but what does that mean? When other companies are building on top of, inside, and around data warehouses, why did we need to build our own and what's special about it?
This post dives into the strategic and technical details of why and how we built our version of the data warehouse.
PostHog vs the modern data stack
The data warehouse space is a crowded one. It's the crown jewel of the modern data stack ecosystem, a concept so amorphous its spawned an entire industry of consultants whose job is to define, sell and maintain the illusion it's working.
We think the modern data stack kinda sucks for most companies. It's excessively complicated, hard to maintain, and widens the gap between engineers and the data they need.
Our solution is to build more of the functionality startups and small teams need from the modern data stack, so we can remove or delay their need for it. We started by building a world-class analytics platform; the data warehouse is the next piece of that puzzle.
We realize some data doesn't fit nicely into our event-based pattern, but teams still need it. This includes data from sources like Stripe, Zendesk and Hubspot. The data warehouse enables them to query this data and combine it with their product data without needing to set up the whole modern data stack.
In doing so, we can:
- Be the source of truth for all product and customer data.
- Be a default tool that every startup needs from the beginning.
What does the PostHog version of a data warehouse look like?
We're never going to reach feature parity with a massive data warehouse company, but we can create 80% of the value for our users with 20% of the effort. This also fits with the PostHog ethos of shipping fast. What did this mean?
Scratch our own itch. We basically wanted to bring revenue, database, and CRM data into PostHog and be able to query it (and we knew other startups wanted the same). This means connections to sources like Stripe, Postgres, and Hubspot.
Relatively simple. No requiring teams to set up a CDP, ETL, DBT, or the other pieces of the modern data stack. It should delay the need to hire a data engineer, but be compatible with them once they do get hired.
Work with our existing products. To start, we wanted to blend product analytics and BI. We have visualizations and SQL querying, they just needed to work with external data. Eventually, the data warehouse should be able to work with the rest of our products.
What we built
There are two major parts to the data warehouse we ended up building and are now releasing: getting data into PostHog and making use of it once there.
Fun fact: The first version of the data warehouse was actually built at our Aruba hackathon. It enabled you to load custom tables from external sources and query them within PostHog.
Receiving department (AKA get data into PostHog)
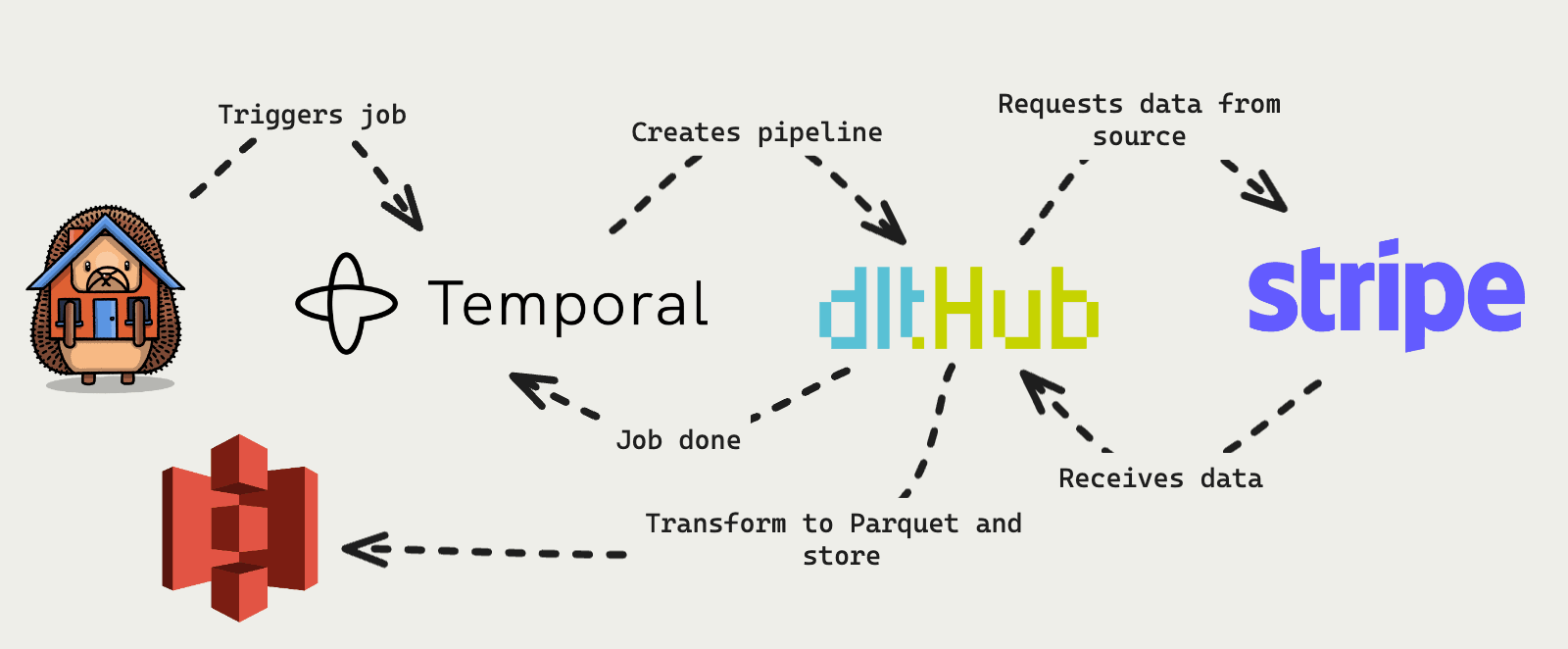
First, we need to schedule workflows to sync data from sources. What better tool to do this with than our good pal Temporal? We already used Temporal in batch exports and elsewhere, so it made sense as a base.
Temporal triggers a job that uses dlthub to create a pipeline to the source. dlt handles requests to the source, pagination, and data transformation. Basically, it makes it easy to connect to sources and get useful data out of them.
The data we pull from sources is serialized as Parquet and stored in S3. We also record the schema of the underlying Parquet data in our metadata store, which gets used in query building.
Overall, this is a flexible format that enables us to build connectors easily. It also enables users to define their own blob storage tables to query with PostHog.
Dispatch department (AKA query data from the warehouse)
You might be saying "cool bro, anyone can upload a table to S3," but it doesn't stop there for us. We have two more tricks up our sleeves when it comes to actually using and querying the data.
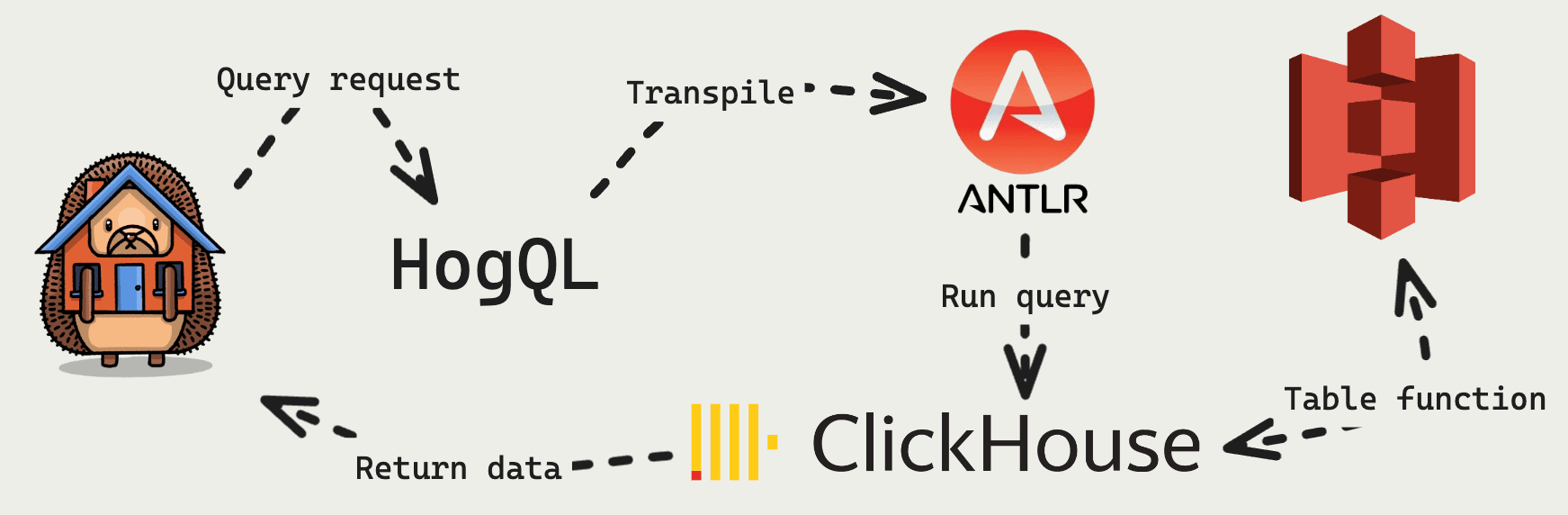
To do querying, we rely on HogQL, our home-built query engine. It transpiles to SQL, but modifies and injects commands and functions into the query to simplify the user experience and optimize queries. For example, it injects null handling, uses materialized columns, and modifies the query based on the source schema. This largely relies on ANTLR.
So, when a user writes a query like select email, address from test_stripe_customer where email like '%posthog.com' in an SQL insight, it gets modified and transformed to:

Where does that query run? In our best friend, ClickHouse (sorry Temporal). ClickHouse powers PostHog. It is the main database we use to store and query event data (among other things). Helpfully for us, ClickHouse provides an S3 table function. This means we can query data using all our existing query logic without needing to create a table for it, or load it first.
Becoming the Django of data stacks
The data warehouse is part of our aim to be like the Django of data stacks. This means we're more opinionated with less flexibility, but easier to get value out of quickly and maintain. We want engineers to self-serve and make use of their data.
Our next step to making that happen is launching the data warehouse and getting it into hands of users (which you're helping with right now). Beyond this, we are focusing on two upgrades:
Making it easier to use. We are adding more source connectors and templates. Improving the reliability and experience of syncing sources.
Integrating it with PostHog. Although you can query sources with SQL insights and visualize data with trends, there is more work needed before the data warehouse is fully integrated. For us, this means more insight types and use with feature flags, cohorts, experimentation, and more.
If this type of work interests you, we're hiring.